Deep Image Matting
The greenscreen will become obsolete, that’s a fact. One way or another new techniques will jump in and will make work of image-matting a much more automated, less time-consuming job. To be fair some alternatives are already been used in Hollywood productions such as the virtual sets used in the latest Disney series The Mandalorian. A set of led screens recreate the environment in real time improving the effects of reflections and allowing the actors to move in a much more realistic set are becoming a thing.
Deep learning techniques are emerging as well, letting the practice of manually cutting out content over background becoming fully automated, with almost no supervision. Now I’ll take a look at a couple of different projects I found.
- MODNet - Is a Green Screen Really Necessary for Real-Time Portrait Matting?
- U-2-Net - Going Deeper with Nested U-Structure for Salient Object Detection
Although they have fairly different architectures they do share the common great advantage to be very easy to test and flexible enough to be tested quickly on different content. U-2-Net has shown already very interesting application capabilites. Just look at the AR Copy Paste project from Cyril Diagne which is just scratching the surface of how these new tools will gradually change the content creation field.
The possible applications of this technique are fairly straightforward and apart from background matting for movies, we see a vast usage of similar tools in our daily life for any video conferencing system at our disposal. Who doesn’t want some custom, weirdly-looking background these days? To be fair there are other promising projects such as Real-Time High-Resolution Background Matting which can give very similar or even better results but most of them are trickier to work with, require auxiliary inputs or they’re simply computationally intensive.
Since I’ve already introduced The Mandalorian I’ll use some shots from the series to test both frameworks. I’ll start with these scene, with one or multiple character and different lighting conditions.
MODNet results



U-2-Net results



I believe they’re doing a decent job extracting the foreground characters from the environment but anyone who has tried cutting out figures in Photoshop knows that the real issue arise when your working on the edges of the character. Any little detail, the hair or even accessories can be troublesome and greatly affect the ability to perform the task well. The MODNet model seems to handle very well a wider range of scenarios and is able to extract details in more refined way, expecially on the boundary of the extracted shape. The U-2-Net is still very good but less precise on the border and the objects direcly related to the character.
It becomes clear that having really detailed masks such the one produced by the MODNet model, can be used right away letting you change the background in a metter of seconds such in this small sample I provide here below.

Let’s move to video content. Here I selected scenes with clear characters in front of the camera.
And surpsingly both models are doing just fine. The time consistency is still the main issue though, with some clear unwanted flickering effect appearing on the alpha mask especially with fast movement on screen.
After some test it becomes clear that MODNet sometimes show these large stains, which are difficult to intepret since they seems to appear with different contents in the input image.
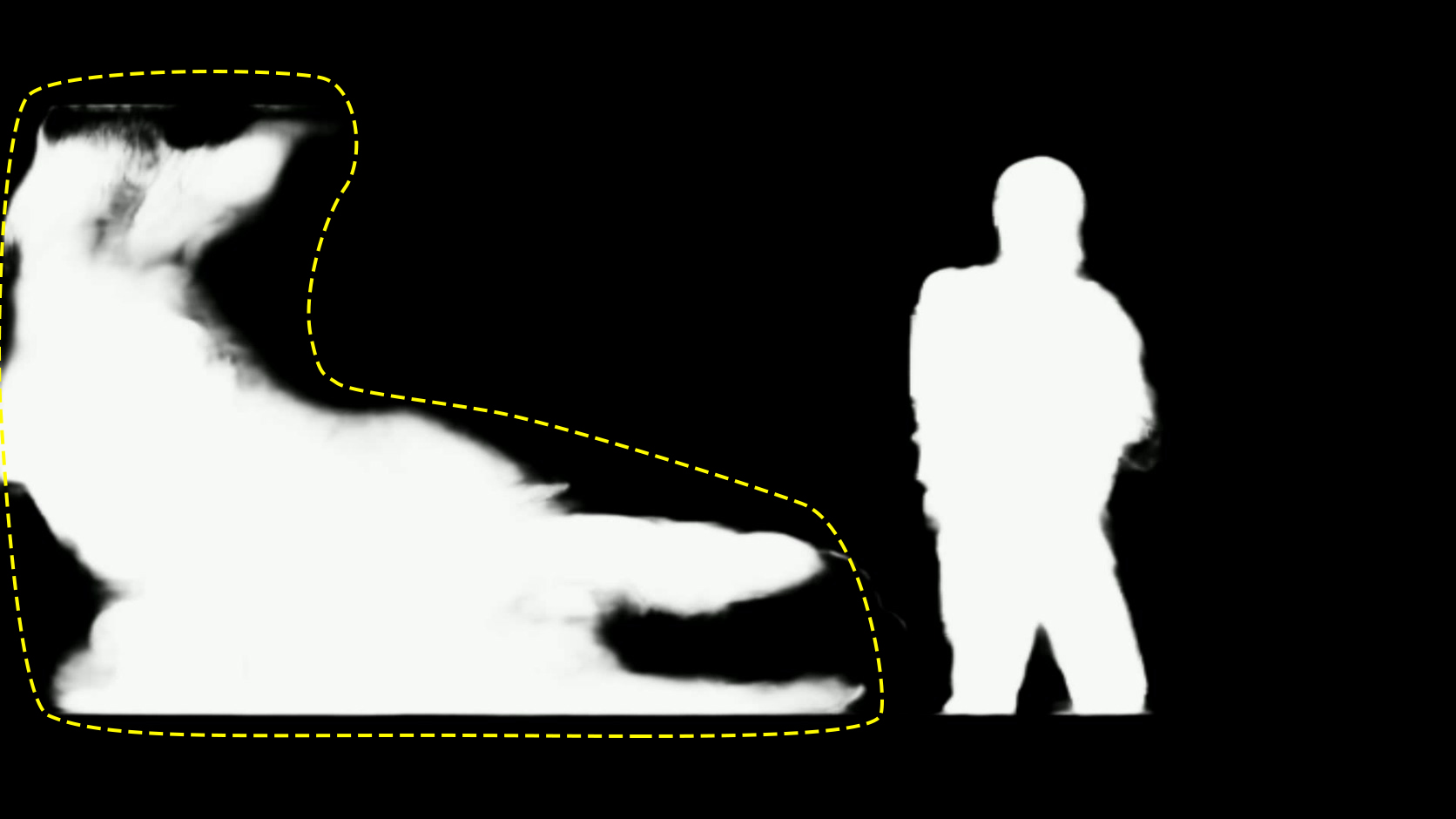
MODnet_Errors
U-2-Net on the other hand is not showing any weird shapes in the alpha mask but at the same time is less precise finding the actual contour of the characters and it definitely struggles handling reflections, such us the one on the armour.
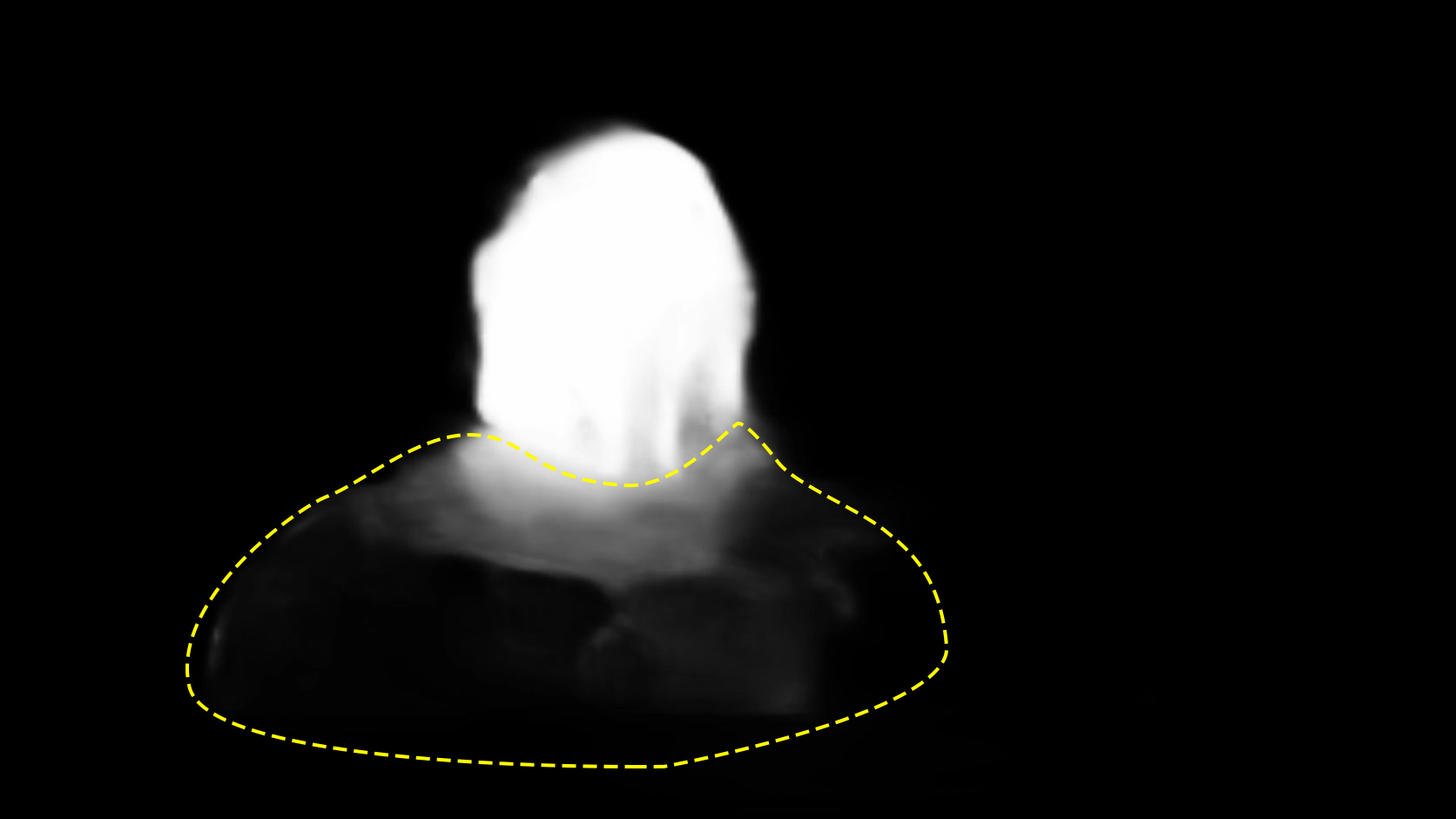
U-2-Net_Errors
Here some more side by side comparison between the two models. Again they both have their flaws but in the context of portrait matting I believe MODNet is doing a better job.


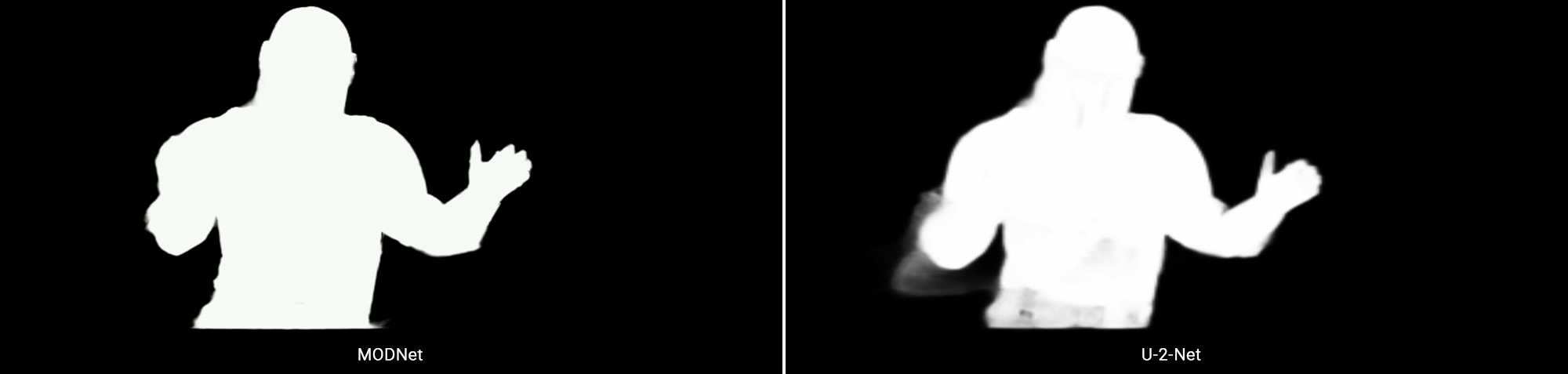
And if you haven’t had enough here’s a longer footage where a much diverse of images are processed. The more we have
Next up some I’ll do some more testing of these models in the wild.