Depth Estimation Battle
Comparison between different depth estimation techniques

It’s been a while since I wanted to test different depth estimation models one against each other. Each one is mainly employing deep neural networks as a backbone algorithm for the extrapolation of the depth map.
I’ve been working with different implementations for a set of projects at fuse*, the studio in which I’m currently working, but I’ve never really made an extensive side by side evaluation. So I’ve collected a few interesting models to test. As everybody knows the Deep Learning field is blossoming and the rate at which new projects are coming out is outrageous, so I’ll probably miss some nice research ones that fit into this category, in that case I’ll probably test them out later.
Processing still images
First I did some tests on single images taking into consideration three models:
- 3D Ken Burns - 3D Ken Burns Effect from a Single Image using PyTorch
- 3D Photo Inpainting - 3D Photography using Context-aware Layered Depth Inpainting
- MiDaS - Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer
To be fair the 3D Photo Inpainting model uses the first version of MiDaS, so in reality I’m evaluating the 3D Ken Burns depth estimation tool and three different iterations of the MiDaS project, with the last update coming in November 2020 and a refined model trained on 10 different datasets.
I won’t get into the technical details and differences between each of the architecture used by these research group but from these simple examples it gets interesting to see how they react and perform.
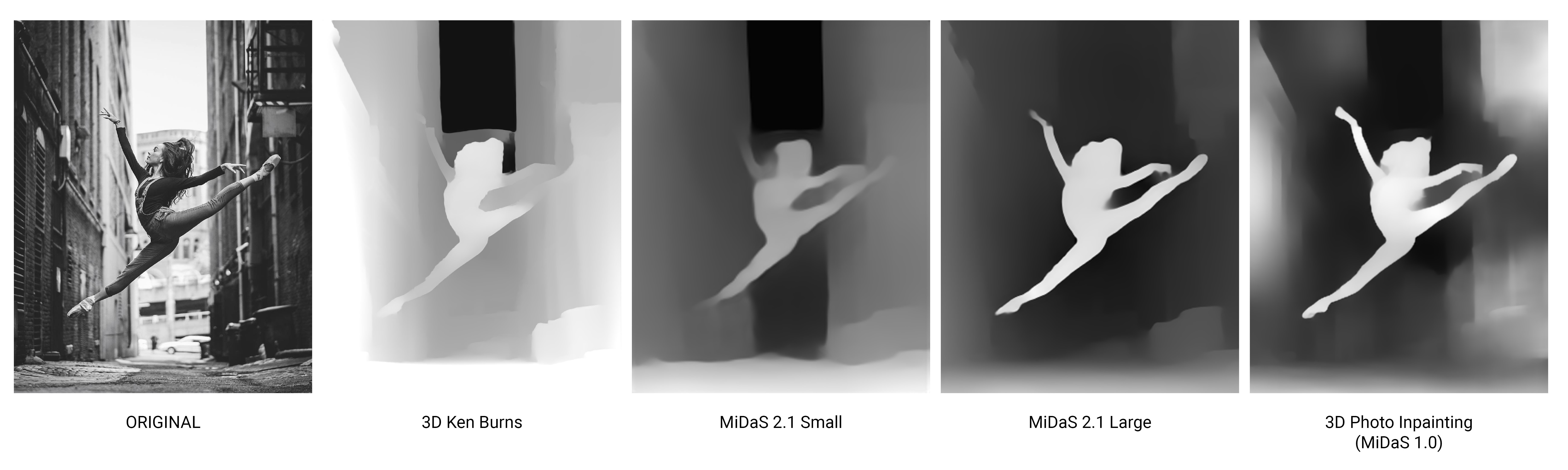
Most of them have been trained on images from street dataset (depth estimation is extremely useful for self-driving car applications) so it seems that generally the buildings are really helping the model to understand better what is going on. When it comes to the human figure of the dancer this are getting a little trickier. The first two models don’t perform very well, and the retrieved depth map of the dancer is getting blurry or totally incorrect in the outer part of the body while the last two seems to have better extracted the outline of the figure from the background environment.
Below, the same models have been applied to a diverse set of images. The depth estimator used for by the 3D Ken Burns project is clearly failing at most of the tasks but the others area clearly doing a good job, given the diversity of the content they’ve been facing. While clearly the smaller MiDaS model is compromising a bit of the accuracy due to the reduced size of the models if process the images way faster, the two last models on the right are the best ones with the v1.0 that seems to grasp more details but it also create some artifacts or cloudy areas where something weird is clearly going on.

As you may have guessed from the names of some of these projects some of the applications revolve around the idea of animating still photos by informing the pixels of their depth information. Even though the depth map is not perfectly matching and the network if forced to guess what is happening in any occuluded part of the image interesting effects can emerge. As shown by these two examples below virtual camera animation can be implemented to give an interesting 3-dimentional look to the picture.


Processing video footage
Images are fine but what about videos. I took the most promising model from the previous test (MiDaS v2.1) and put it head to head with another compelling model developed by the Facebook Research group called Consistent Video Depth Estimation. Unlike the the models used before this one is specifically developed to deal with continuous stream of images and the algorithm should reconstruct dense, geometrically consistent depth for all pixels in the video. At test time the network is fine-tuned to satisfy geometric constraints achieving higher accuracy and higher degree of geometric consistency.
The real big drawback, though, is timing. With this video 4 seconds long, the whole process took 90 minutes to perform on a decent gpu so it gets difficult to try out things on the fly (which is my jam). To optimize this process images are also resized so most of the details are lost even before any computation occurs.
The process starts with a monocular depth estimation, and it looks ok. Doesn’t seem to suffer from any pariticular problem.

When the additional process kicks in, the background seems much more stable and without artifacts but the dancer figures suddenly are completely miscalculated. It probably needs some more testing to really figure out what is actually causing the incorrect estimation . I would say that the camera motion occuring at some point of the footage and the reflections on the floor are not helping.



Overall the MiDaS 2.1 version looks better to me. A lot of flickering over the whole length of the clip but no really evident errors are appearing and
I’ll definitely do some more extensive testing on videos, trying the models on a diverse set of content and increasing the amount of details extracted. Another interesting application would be to have a real time depth-estimation camera application creating an interesting competition with IR cameras.